一年一度的python小程序编写系列之——断点续传下载软件。
一、HTTP断点续传原理
其实HTTP断点续传原理比较简单,在HTTP数据包中,可以增加Range头,这个头以字节为单位指定请求的范围,来下载范围内的字节流。如:
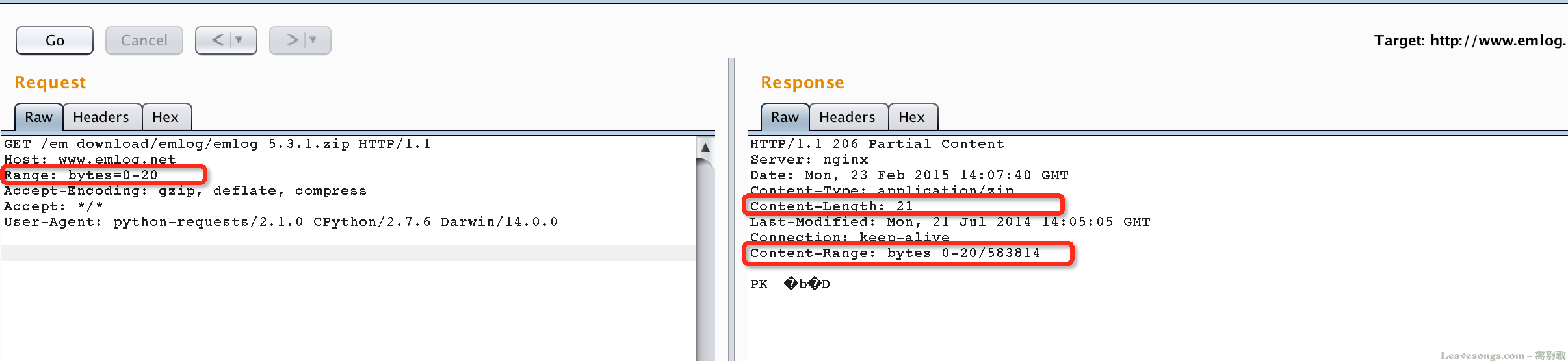
如上图勾下来的地方,我们发送数据包时选定请求的内容的范围,返回包即获得相应长度的内容。所以,我们在下载的时候,可以将目标文件分成很多“小块”,每次下载一小块(用Range标明小块的范围),直到把所有小块下载完。
当网络中断,或出错导致下载终止时,我们只需要记录下已经下载了哪些“小块”,还没有下载哪些。下次下载的时候在Range处填写未下载的小块的范围即可,这样就能构成一个断点续传。
其实像迅雷这种多线程下载器也是同样的原理。将目标文件分成一些小块,再分配给不同线程去下载,最后整合再检查完整性即可。
二、Python下载文件实现方式
我们仍然使用之前介绍过的requests库作为HTTP请求库。
先看看这段文档:http://docs.python-requests.org/en/latest/user/advanced/#body-content-workflow,当请求时设置steam=True的时候就不会立即关闭连接,而我们以流的形式读取body,直到所有信息读取完全或者调用Response.close关闭连接。
所以,如果要下载大文件的话,就将steam设置为True,慢慢下载,而不是等整个文件下载完才返回。
stackoverflow上有同学给出了一个简单的下载demo:
def download_file(url): local_filename = url.split('/')[-1] # NOTE the stream=True parameter r = requests.get(url, stream=True) with open(local_filename, 'wb') as f: for chunk in r.iter_content(chunk_size=1024): if chunk: # filter out keep-alive new chunks f.write(chunk) f.flush() return local_filename
这基本上就是我们核心的下载代码了。
三、断点续传结合大文件下载
好,我们结合这两个知识点写个小程序:支持断点续传的下载器。
我们可以先考虑一下需要注意的有哪些点,或者可以添加的功能有哪些:
- 用户自定义性:可以定义cookie、referer、user-agent。如某些下载站检查用户登录才允许下载等情况。
- 很多服务端不支持断点续传,如何判断?
- 怎么去表达进度条?
- 如何得知文件的总大小?使用HEAD请求?那么服务器不支持HEAD请求怎么办?
- 下载后的文件名(header中可能有filename,url中也有filename,用户还可以自己指定filename),怎么处理?还要考虑windows不允许哪些字符做文件名。
- 如何去分块,是否加入多线程。
其实想一下还是有很多疑虑,而且有些地方可能一时还解决不了。先大概想一下各个问题的答案:
- headers可以由用户自定义
- 正式下载之前先HEAD请求,得到服务器status code是否是206,header中是否有Range-content等标志,判断是否支持断点续传。
- 可以先不使用进度条,只显示当前下载大小和总大小
- 在HEAD请求中匹配出Range-content中的文件总大小,或获得content-length大小(当不支持断点续传的时候会返回总content-length)。如果不支持HEAD请求或没有content-type就设置总大小为0.(总之不会妨碍下载即可)
- 文件名优先级:用户自定义 > header中content-disposition > url中的定义,为了避免麻烦,我这里和linux下的wget一样,忽略content-disposition的定义。如果用户不指定保存的用户名的话,就以url中最后一个“/”后的内容作为用户名。
- 为了稳定和简单,不做多线程了。如果不做多线程的话,我们分块就可以按照很小来分,如1KB,然后从头开始下载,一K一K这样往后填充。这样避免了很多麻烦。当下载中断的时候,我们只需要简单查看当前已经下载了多少字节,就可以从这个字节后一个开始继续下载。
解决了这些疑问,我们就开始动笔了。实际上,疑问并不是在未动笔的时候干想出来的,基本都是我写了一半突然发现的问题。
def download(self, url, filename, headers = {}): finished = False block = self.config['block'] local_filename = self.remove_nonchars(filename) tmp_filename = local_filename + '.downtmp' if self.support_continue(url): # 支持断点续传 try: with open(tmp_filename, 'rb') as fin: self.size = int(fin.read()) + 1 except: self.touch(tmp_filename) finally: headers['Range'] = "bytes=%d-" % (self.size, ) else: self.touch(tmp_filename) self.touch(local_filename) size = self.size total = self.total r = requests.get(url, stream = True, verify = False, headers = headers) if total > 0: print "[+] Size: %dKB" % (total / 1024) else: print "[+] Size: None" start_t = time.time() with open(local_filename, 'ab') as f: try: for chunk in r.iter_content(chunk_size = block): if chunk: f.write(chunk) size += len(chunk) f.flush() sys.stdout.write('\b' * 64 + 'Now: %d, Total: %s' % (size, total)) sys.stdout.flush() finished = True os.remove(tmp_filename) spend = int(time.time() - start_t) speed = int(size / 1024 / spend) sys.stdout.write('\nDownload Finished!\nTotal Time: %ss, Download Speed: %sk/s\n' % (spend, speed)) sys.stdout.flush() except: import traceback print traceback.print_exc() print "\nDownload pause.\n" finally: if not finished: with open(tmp_filename, 'wb') as ftmp: ftmp.write(str(size))
这是下载的方法。首先if语句调用self.support_continue(url)判断是否支持断点续传。如果支持则从一个临时文件中读取当前已经下载了多少字节,如果不存在这个文件则会抛出错误,那么size默认=0,说明一个字节都没有下载。
然后就请求url,获得下载连接,for循环下载。这个时候我们得抓住异常,一旦出现异常,不能让程序退出,而是正常将当前已下载字节size写入临时文件中。下次再次下载的时候读取这个文件,将Range设置成bytes=(size+1)-,也就是从当前字节的后一个字节开始到结束的范围。从这个范围开始下载,来实现一个断点续传。
判断是否支持断点续传的方法还兼顾了一个获得目标文件大小的功能:
def support_continue(self, url): headers = { 'Range': 'bytes=0-4' } try: r = requests.head(url, headers = headers) crange = r.headers['content-range'] self.total = int(re.match(ur'^bytes 0-4/(\d+)$', crange).group(1)) return True except: pass try: self.total = int(r.headers['content-length']) except: self.total = 0 return False
用正则匹配出大小,获得直接获取headers['content-length'],获得将其设置为0.
核心代码基本上就是这些,再就是一些设置了,各位更可以去github直接看:https://github.com/phith0n/py-wget/blob/master/py-wget.py
运行来获取一下emlog最新的安装包:
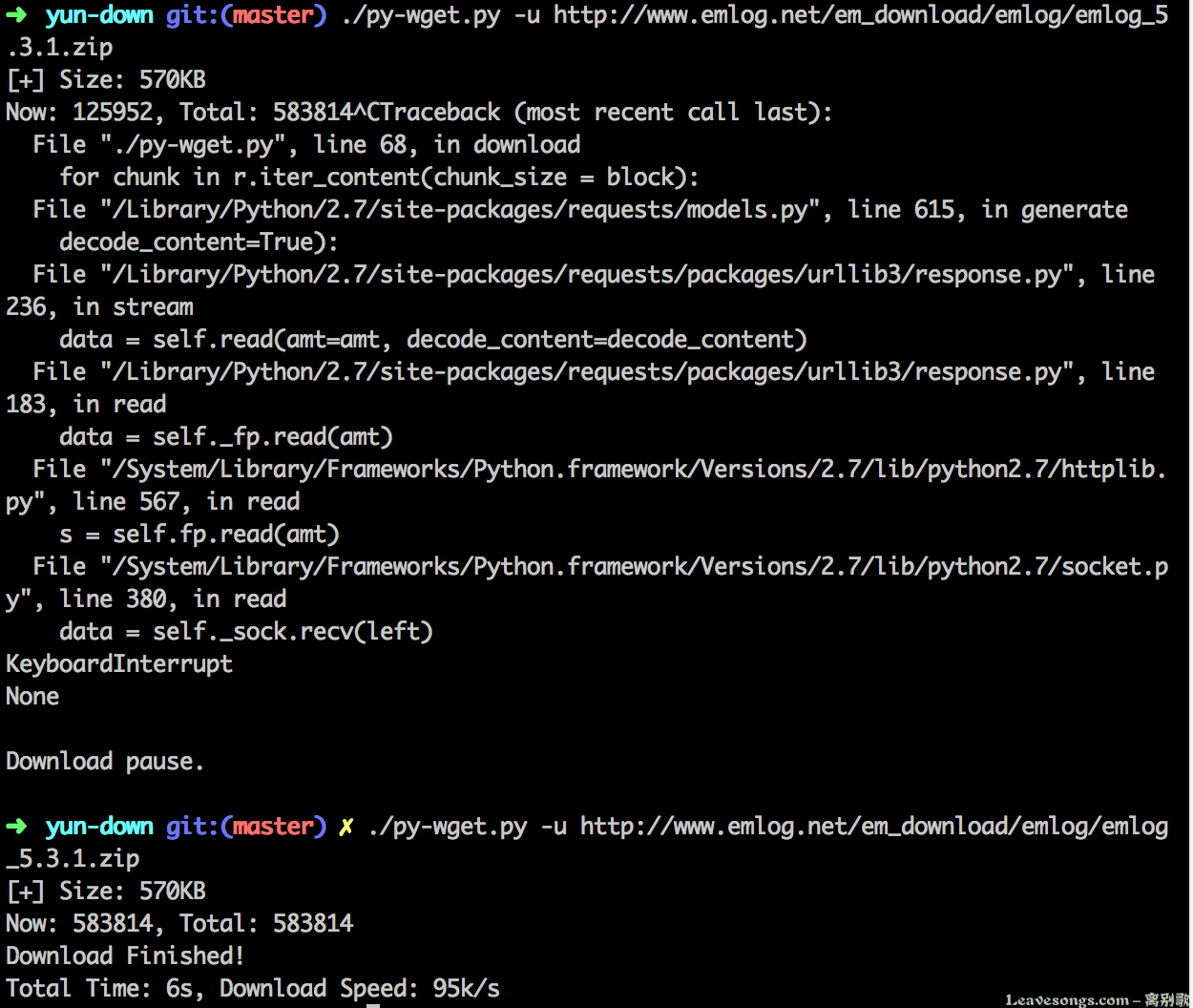
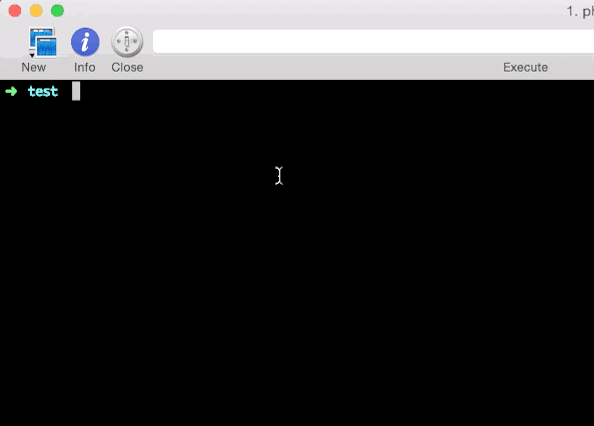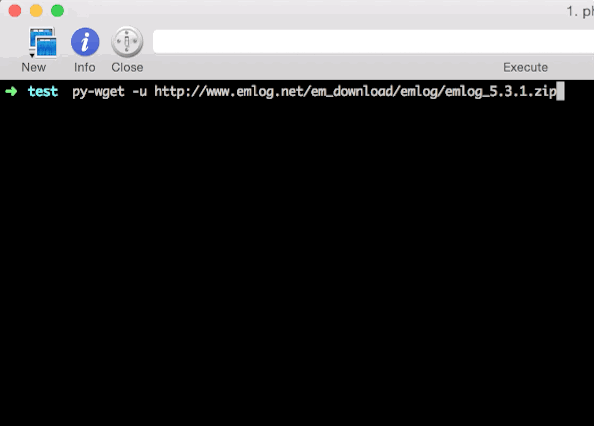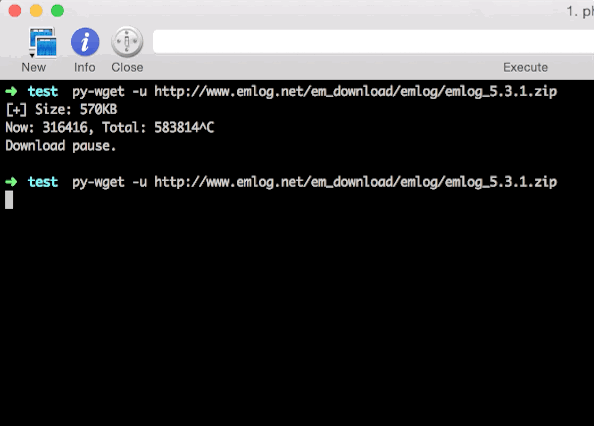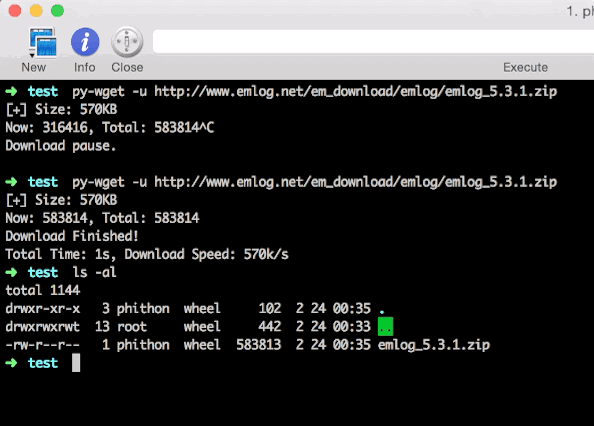
中间我按Contrl + C人工打断了下载进程,但之后还是继续下载,实现了“断点续传”。但在我实际测试过程中,并不是那么多请求可以断点续传的,所以我对于不支持断点续传的文件这样处理:重新下载。
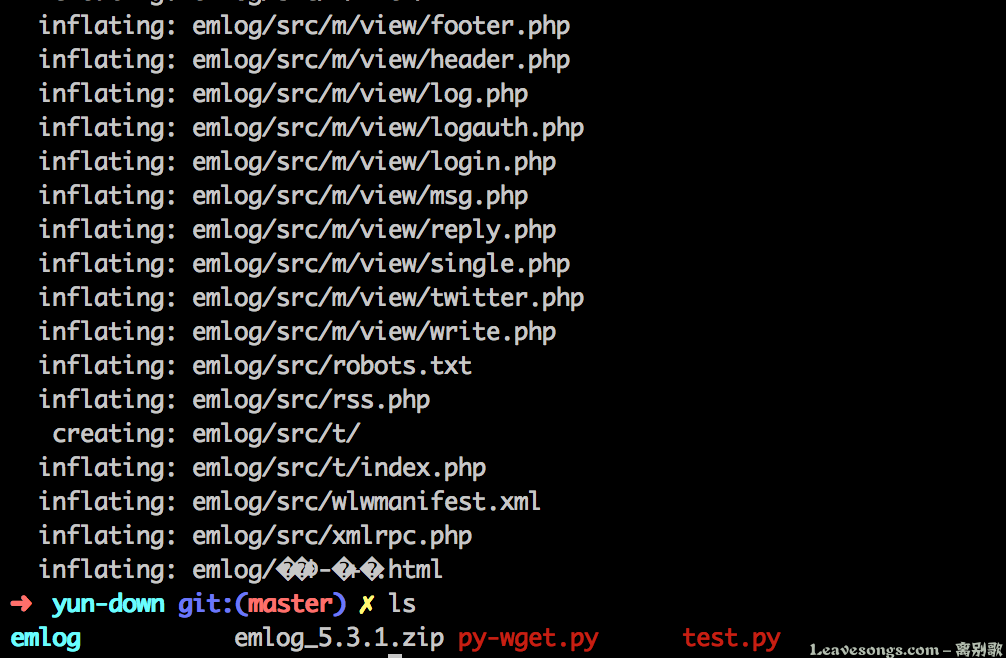
下载后的压缩包正常解压,也充分证明了下载的完整性:
做了个小动图:
如果你想把我的这个小脚本当一个工具来用的话,可以查看github下的说明:https://github.com/phith0n/py-wget。







